
Data aggregator
A company that collect data from various sources and consolidates it into one place to make it easier for businesses, researchers, or individuals to access and analyze
Learn moreTrain your AI models on verifiable data with RAG
Home > Data Glossary > Retrieval-Augmented Generation
Retrieval-augmented generation (RAG) is an artificial intelligence (AI) technique that combines information retrieval with large language model (LLM) generation. Rather than relying only on pre-trained model parameters, RAG acquires relevant external data from a knowledge base, vector database, or enterprise repository, and injects it into the model’s context window before generating a response.
By doing so, RAG provides a trusted context for AI outputs to improve accuracy, reduce hallucinations, and provide verifiable citations.
Generative AI models are powerful, but they are prone to “hallucinations”—answers that are convincing but inaccurate. In high-stakes environments like legal research, due diligence, compliance, and investigative journalism, this can create risk.
RAG reduces these risks by:
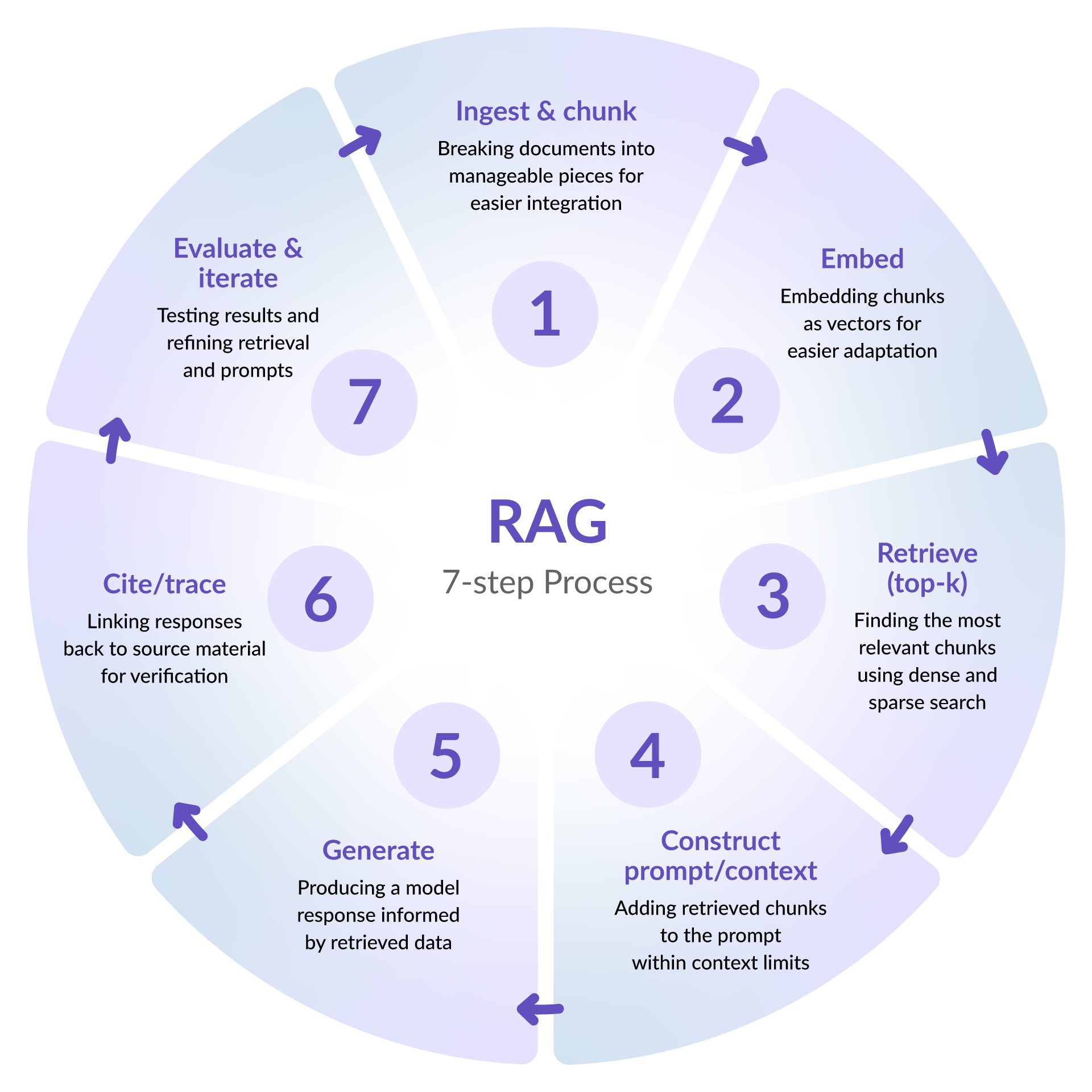
RAG typically follows a seven-step process:
This process is cyclical, allowing the RAG to evolve and improve as the retrieval processes are refined and knowledge is updated.
In order to operate effectively, RAG has four main components that work together to guide the core workflow:
Using a RAG model presents plenty of benefits for organizations looking to implement more artificial intelligence systems into their workflows:
While RAG is noted for its improved accuracy and ability to provide greater context for responses, there are limitations and risks associated, including:
As with all artificial intelligence integration, human oversight is needed to ensure quality and accuracy.
The implementation and creation of RAG systems can be internally built or purchased through an outside provider. There are benefits to each approach.
|
Factor |
Build |
Buy |
|
Control |
Full customization |
Pre-built integrations |
|
Speed |
Longer setup |
Faster deployment |
|
Maintenance |
Ongoing upkeep |
Vendor-managed |
|
Compliance |
Custom to jurisdiction |
Vendor-certified |
The right approach for your organization will depend on your resources, requirements, personnel, and available time for deployment.
To ensure the greatest success with RAG processes, consider:
Various metrics and testing approaches can be used to measure the quality of your RAG systems:
To ensure consistent quality and limit risk, it is important to establish guardrails for trusted RAG implementation:
Retrieval-Augmented Generation can be used to assist professionals in data collection in a variety of fields, including:
While exhibiting similar properties, RAG offers different has some key differences to other artificial intelligence techniques.
|
Feature |
RAG |
Fine-tuning |
|
Goal |
Ground responses in fresh data |
Specialize model knowledge |
|
Data need |
Document corpus |
Labeled datasets |
|
Maintenance |
Ongoing ingestion |
Retraining cycles |
|
Latency |
Moderate |
Low |
|
Risk |
Retrieval gaps |
Outdated model |
|
Term |
Retrieval-Augmented Generation |
|
Definition |
Combines information retrieval with generative AI to ground outputs in external sources |
|
Used By |
Data scientists, researchers, compliance teams, knowledge managers |
|
Key Benefit |
Improves factual accuracy and provides citable, trustworthy AI responses |
|
Example Tool |
Nexis+ AI, Nexis Data+ |
LexisNexis can help ensure your AI insights are built on a foundation of credible data. Whether you're interested in leveraging the LexisNexis library of business, news, and legal content within your own AI models of ours, we have a solution for you.
Nexis+ AI applies RAG to business research, grounding outputs in trusted, authoritative sources. Research teams benefit from enhanced accuracy, natural language queries, and transparent citations—all built on decades of LexisNexis expertise. With Nexis+ AI, organizations can:
By embedding Nexis+ AI into a RAG framework, organizations can ground data in relevant contexts, creating a more accurate and reliable framework.
Nexis Data+ provides high-quality, licensed datasets that enrich RAG workflows across industries. By supplying structured legal, news, and business content, it ensures that generative AI outputs are anchored in reliable, compliant information. With Nexis Data+, organizations can:
Yes, provided access controls, redaction, and audit logging are in place.
Use Nexis+ AI to conduct research using accurate, licensed data —or talk to an expert about how you can use LexisNexis data in your organization’s existing AI models.
Connect with a LexisNexis expert to discuss how to best support your organization's AI and RAG initiatives.
LexisNexis, a division of RELX Inc., may contact you in your professional capacity with information about our other products, services, and events that we believe may be of interest. You can manage your communication preferences via our Preference Center. You can learn more about how we handle your personal data and your rights by reviewing our Privacy Policy.
